
](https://cdn-images-1.medium.com/max/2000/0*WdYZ4xKi-0jFdqj4.jpg) “Evolutionary perspective” by Allan Bao
“Evolutionary perspective” by Allan Bao
Frequently in software development, we hear about some new trend, some new technology, a better way to use what we already have “working”. Event sourcing was one of those trends that as much I saw people studying for the last few years and talking about as a silver bullet, they find out that maybe was not so easy or even didn’t understand it at all. My purpose here is to explain Event Sourcing, without a pet framework, how it works and which decisions can drive you to go “full” event sourcing.
Here is our roadmap, those topics will be in order to create something that makes sense once you reach the end of this article.
 Roadmap
Roadmap
Remembering that one is not necessarily better than the other, my point here is which decisions can you take to decide to use Event sourcing.
Monolithic Architecture
Almost the first architecture every non-millennial worked. A monolith is a big block of code, normally with backend and frontend in the same code base and has the advantages of being fast to prototype and easy to deploy, but it has some famous drawbacks:
](https://cdn-images-1.medium.com/max/2000/1*fmDIsQhMp9HvJAngSJTWcw.jpeg) “why?” by imgflip
“why?” by imgflip
-
The large monolithic code base intimidates developers, especially ones who are new to the team
-
Overloaded IDE
-
Overloaded web container
-
Continuous deployment is difficult
-
Scaling the application can be difficult
-
An obstacle to scaling development
-
Requires a long-term commitment to a technology stack
Some examples of frameworks that have a monolithic architecture by nature are Rails, Django, Play Framework.
Micro-services architecture
With a micro-service architecture, we could divide and decouple services by responsibility, this has a lot of advantages and today is the most common architecture. This trend is commonly associated with agile teams and projects where you can have teams working only in some “responsibilities” and making incrementing changes without impacting the whole project.
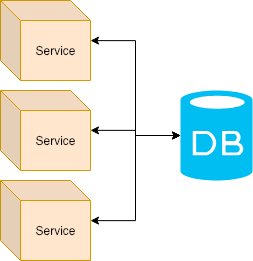 Micro-services example
Micro-services example
This approach resolves some problems of the monolithic architecture.
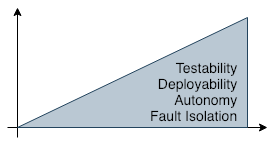 Micro-services advantages
Micro-services advantages
-
Testability, easy to test
-
Deployability, easy to deploy
-
Autonomy, decoupled from “most” of the system
-
Fault isolation
Today, a lot of frameworks can be used to create a micro-service. Some of them are Spring, Micronauts, Sinatra, Flask, Finatra and so on.
Database per service
Microservices can have different database necessities and business rules for changes. For that, we can have a single database for each microservice.
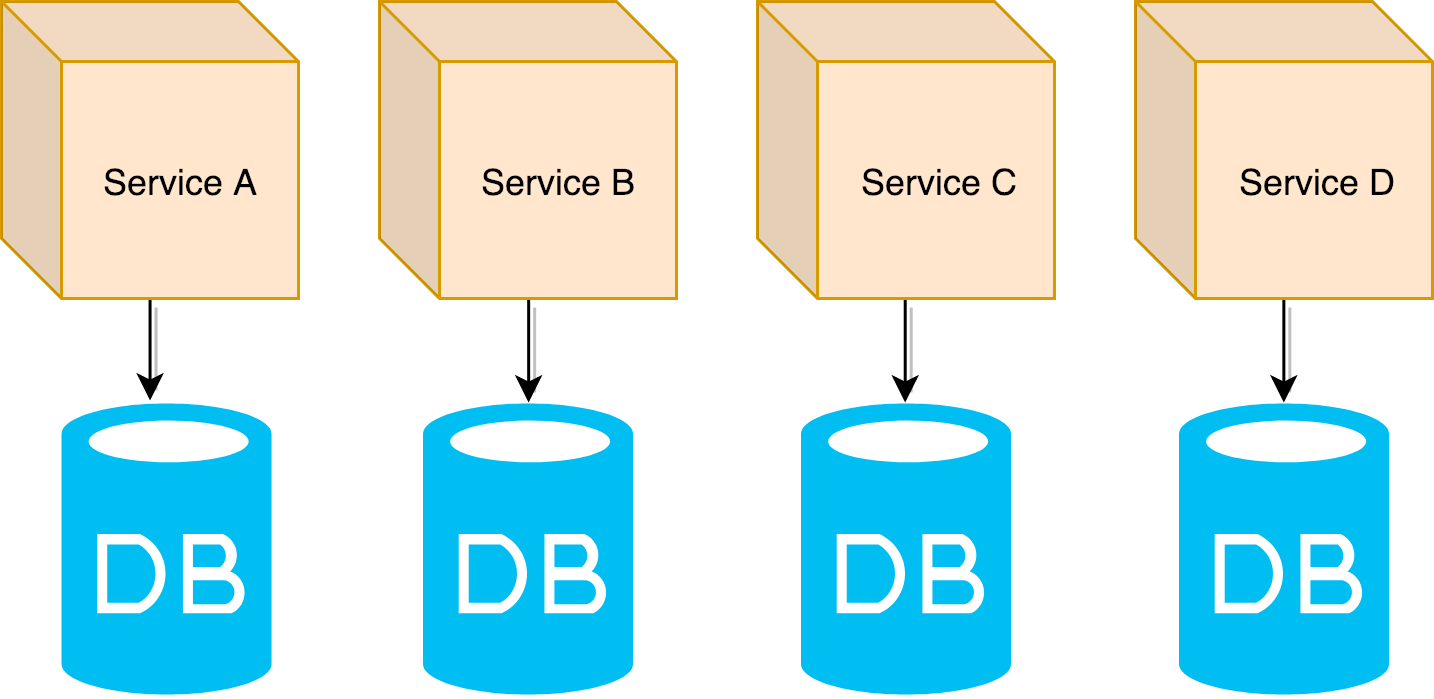 Database segregation
Database segregation
](https://cdn-images-1.medium.com/max/3052/1*IVBg6yjFvsTC5y14O_y9aA.png) “Independency” by imgflip
“Independency” by imgflip
This approach has some benefits:
- Low coupling and high autonomy, since the database now is only accessible by API, it doesn’t matter to the other services how you store data. The microservice now can choose the best technology and model it’s own data to better solve the challenges.
And some drawbacks:
-
High complexity, develop queries that spread across multiple databases is not straightforward.
-
Implement queries that join data, now in multiples databases, is challenging.
-
Maintain database consistency is tricky.
Sagas
With a microservices architecture, comes the problem of “how to maintain consistency across services?”, for that purpose exists the concept of Saga. Saga is a sequence of transactions and each local transaction emits an event or a message that triggers the next process in a transaction.
-
It enables an application to maintain data consistency across multiple services without using distributed transactions
-
The programming model is more complex. For example, a developer must design compensating transactions that explicitly undo changes made earlier in a saga.
-
In order to be reliable, a service must atomically update its database and publish an event.
It’s also important to understand the difference between message and event:
-
Message is addressed to someone.
-
Event is something that happened and someone can react to that.
Sagas — Choreography
An event triggers another step in the process.
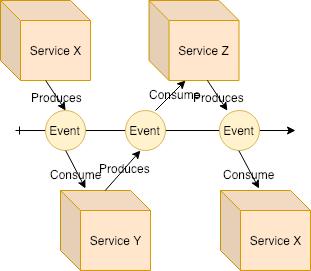 Choreography example
Choreography example
Choreography is commonly known as “event-oriented” architecture.
Sagas — Orchestration
A process emits messages to another service.
Event Sourcing
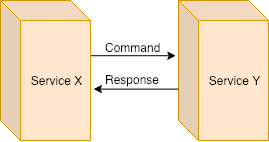
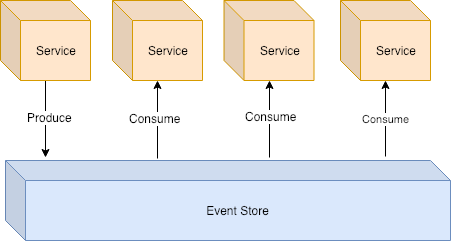
Event sourcing is an architecture pattern that focuses on maintaining the source of truth of your business as an immutable sequence of events. This sequence of events will be time-based and the current state of your business will be a reflection of the sequence of events, not of the last event.
 A sequence of events through time
A sequence of events through time
This sequence of events is persisted in an event store. An event store and it relation with the microservices have some peculiarities.
Atomicity
When persisting an event to the event store, this should be atomic. By atomic it means:
An atomic operation, by definition, is an operation that occurs in only one step making impossible to have “half operation”.
Causal consistency
With the asynchronous nature of event sourcing:
The causal consistency means that all operations are related in some way. If event A means the trigger to event B, they are related and processed in order.
With that in mind, the event store should persist the events in order and broadcast any new event.
 Event Sourcing overview
Event Sourcing overview
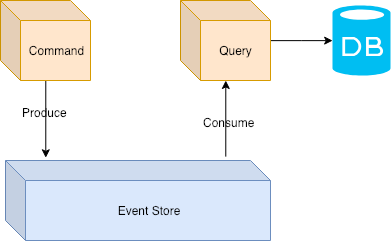
CQRS
With event sourcing, we can decouple which services do queries and which services generate commands.
CQRS or Command Query Responsibility Segregation
 CQRS example
CQRS example
Event Store
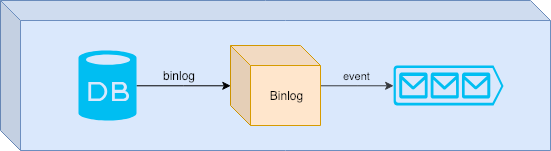
We could, in order to simplify what the event store does, implement an event store as below:
 “Exploded” event store
“Exploded” event store
Different from sagas, we should do it atomically. In the image above, we persist in the database and from a binlog generated by the database we produce events. These events are then consumed by other micro-services.
But, why?
Nubank (a fintech from Brazil) went to an Event Sourcing approach in order to gain scalability and resilience. They used Kafka as an event store.
Scalability. Using Kafka as an event store, they were able to at any time scale they services and replay the last events in order to be even with the event store and serve as a source of truth for the business.
Resilience. With event sourcing, they don’t lose events anymore. Once an event was accepted by the event store, it will be broadcast to any micro-service subscribed to that change.
Simplifying their solution:
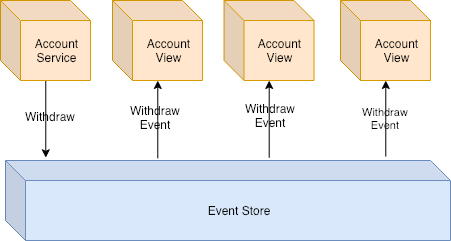 Nubank simplified solution
Nubank simplified solution
The idea is when the account has any kind of movement. The event store will generate events to all micro-services subscribed to that event. Those micro-services will receive this event and sensibilize the local database as bellow.
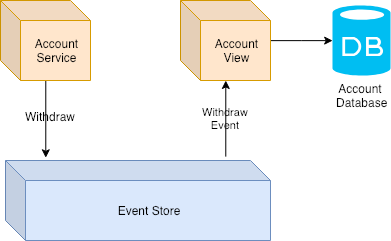 Nubank simplified flow
Nubank simplified flow
By receiving an event and storing its changes in a local denormalized database they get less latency for queries and be totally decoupled of other services.
](https://cdn-images-1.medium.com/max/2000/1*8OBRLbdGwj1RDRkUA14uKQ.jpeg) “Because Sponge Bob knows it” by imgflip
“Because Sponge Bob knows it” by imgflip
An event sourcing architecture has some drawbacks:
-
Duplicated data, because of the denormalized databases, it could have duplicated data.
-
More cloud consuming, once every micro-service replica has its own database.
-
Complexity, because of the CQRS decoupling, it may spread micro-services that with time could become difficult to maintain.
Event sourcing doesn’t solve all your problems, and in any case is a silver bullet. Most of the times, it doesn’t go forward because of misunderstanding of the purposes and which problems it resolves. What are your thoughts about it? Which do you think will be the next trend? (besides serverless…)
Strongly based on:
